Distributed Proximal Policy Optimization (DPPO) (Tensorflow)
学习资料:
- 全部代码
- 什么是 Actor-Critic 短视频
- 我的 A3C Python 教程
- 我的 Python Threading 多线程教程
- 强化学习实战
- OpenAI 的 PPO 论文 Proximal Policy Optimization
- Google DeepMind 的 DPPO 论文 Emergence of Locomotion Behaviours in Rich Environments
要点 ¶
根据 OpenAI 的官方博客, PPO 已经成为他们在强化学习上的默认算法. 如果一句话概括 PPO: OpenAI 提出的一种解决 Policy Gradient 不好确定 Learning rate (或者 Step size) 的问题. 因为如果 step size 过大, 学出来的 Policy 会一直乱动, 不会收敛, 但如果 Step Size 太小, 对于完成训练, 我们会等到绝望. PPO 利用 New Policy 和 Old Policy 的比例, 限制了 New Policy 的更新幅度, 让 Policy Gradient 对稍微大点的 Step size 不那么敏感.
因为 PPO 是基于 Actor-Critic 算法, 所以还不了解 Actor-Critic 的朋友们, 强烈推荐你在这个短视频
和这个 Python 教程中获得了解,
下面是这节内容的效果提前看:
OpenAI 和 DeepMind 的 Demo ¶
OpenAI 的 Demo:
DeepMind 的 Demo:
 (Tensorflow)")
 (Tensorflow)")
看 Demo 他们都说 PPO 在复杂环境中有更好的表现. 那我也就提起性子, 把 papers 看了一遍.
算法 ¶
PPO 的前生是 OpenAI 发表的 Trust Region Policy Optimization, 但是 Google DeepMind 看过 OpenAI 关于 Trust Region Policy Optimization 的 conference 后, 却抢在 OpenAI 前面 (2017年7月7号) 把 Distributed PPO给先发布了. 我觉得 DeepMind 有点抢, 这让 OpenAI 有点难堪. 不过 OpenAI 还是在 2017年7月20号 发表了一份拿得出手的 PPO 论文 (估计是突然看到了 Google 抢了自己的东西, 所以赶紧把自己的也发了).
所以我也总结了一下 DeepMind 和 OpenAI 的两篇 papers, 基于他们两者的优势, 写下了这份教程, 还有练习代码.
OpenAI PPO 论文里给出的算法… 写得也太简单了 (注意他们这个 PPO 算法应该算是单线程的):
 (Tensorflow)")
看了上面的主结构, 觉得少了很多东西. 这让我直接跑去 DeepMind 的 Paper 看他们总结 OpenAI conference 上的 PPO 的代码:
 (Tensorflow)")
总的来说 PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL. Critic 的 loss 好说, 就是减小 TD error.
而 Actor 的就是在 old Policy 上根据 Advantage (TD error) 修改 new Policy, advantage 大的时候, 修改幅度大, 让 new Policy 更可能发生.
而且他们附加了一个 KL Penalty (惩罚项, 不懂的同学搜一下 KL divergence),
简单来说, 如果 new Policy 和 old Policy 差太多, 那 KL divergence 也越大,
我们不希望 new Policy 比 old Policy 差太多, 如果会差太多, 就相当于用了一个大的 Learning rate,
这样是不好的, 难收敛.
关于 DeepMind 在这篇 paper 中提出的 DPPO 算法, 和怎么样把 OpenAI 的 PPO 多线程. 我们之后在下面细说, 我们先把简单的 PPO 算法给实现.
简单 PPO 的主结构 ¶
我们用 Tensorflow 搭建神经网络, tensorboard 中可以看清晰的看到我们是如果搭建的:
 (Tensorflow)")
图中的 pi 就是我们的 Actor 了. 每次要进行 PPO 更新 Actor 和 Critic 的时候, 我们有需要将 pi 的参数复制给 oldpi.
这就是 update_oldpi 这个 operation 在做的事. Critic 和 Actor 的内部结构, 我们不会打开细说了. 因为就是一堆的神经网络而已.
这里的 Actor 使用了 normal distribution 正态分布输出动作.
这个 PPO 我们可以用一个 Python 的 class 代替:
class PPO(object):
def __init__(self):
# 建 Actor Critic 网络
# 搭计算图纸 graph
def update(self, s, a, r):
# 更新 PPO
def choose_action(self, s):
# 选动作
def get_v(self, s):
# 算 state value
而这个 PPO 和 env 环境的互动可以简化成这样.
ppo = PPO()
for ep in range(EP_MAX):
s = env.reset()
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
env.render()
a = ppo.choose_action(s)
s_, r, done, _ = env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize reward, 发现有帮助
s = s_
# 如果 buffer 收集一个 batch 了或者 episode 完了
if (t+1) % BATCH == 0 or t == EP_LEN-1:
# 计算 discounted reward
v_s_ = ppo.get_v(s_)
discounted_r = []
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = batch(buffer_s, buffer_a, discounted_r)
# 清空 buffer
buffer_s, buffer_a, buffer_r = [], [], []
ppo.update(bs, ba, br) # 更新 PPO
了解了这些更新步骤, 我们就来看看如何更新我们的 PPO. 我们更新 Critic 的时候是根据 刚刚计算的 discounted_r 和自己分析出来的
state value 这两者的差 (advantage). 然后最小化这个差值:
class PPO:
def __init__(self):
self.advantage = self.tfdc_r - self.v # discounted reward - Critic 出来的 state value
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
在更新 Actor 的时候, 其实有两种方式, 一种是用之前提到的 KL penalty 来更新.
 (Tensorflow)")
我在代码中也写上的这种方式的计算图纸要怎么搭, 不过还有一种是 OpenAI 在 PPO 这篇 paper 中提到的 clipped surrogate objective,
surrogate objective 就是这个 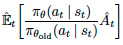 . 他们实验中得出的结论说:
. 他们实验中得出的结论说: clipped surrogate objective 要比 KL penalty 形式好.
那 clipped surrogate objective 到底是什么呢? 其实就是限制了 surrogate 的变化幅度, 和 KL 的规则差不多.
 (Tensorflow)")
这里的 r(theta) 是 (New Policy/Old Policy) 的比例, 和前面的公式一样.
我在代码中把这两种都写上了, 如果觉得我这些代码省略的很严重, 请直接前往我的 Github 看全套代码.
class PPO:
def __init__(self):
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
with tf.variable_scope('loss'):
with tf.variable_scope('surrogate'):
ratio = pi.prob(self.tfa) / oldpi.prob(self.tfa)
surr = ratio * self.tfadv # surrogate objective
if METHOD['name'] == 'kl_pen': # 如果用 KL penatily
self.tflam = tf.placeholder(tf.float32, None, 'lambda')
kl = kl_divergence(oldpi, pi)
self.kl_mean = tf.reduce_mean(kl)
self.aloss = -(tf.reduce_mean(surr - self.tflam * kl))
else: # 如果用 clipping 的方式
self.aloss = -tf.reduce_mean(tf.minimum(
surr,
tf.clip_by_value(ratio, 1.-METHOD['epsilon'], 1.+METHOD['epsilon'])*self.tfadv))
with tf.variable_scope('atrain'):
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
好了, 接下来就是最重要的更新 PPO 时间了, 同样, 如果觉得我这些代码省略的很严重, 请直接前往我的 Github 看全套代码.
注意的是, 这个 update 的步骤里, 我们用 for loop 更新了很多遍 Actor 和 Critic, 在 loop 之前, pi 和 old pi 是一样的,
每次 loop 的之后, pi 会变动, 而 old pi 不变, 这样这个 surrogate 就会开始变动了. 这就是 PPO 的精辟.
class PPO:
def update(self, s, a, r):
# 先要将 oldpi 里的参数更新 pi 中的
self.sess.run(self.update_oldpi_op)
# 更新 Actor 时, kl penalty 和 clipping 方式是不同的
if METHOD['name'] == 'kl_pen': # 如果用 KL penalty
for _ in range(A_UPDATE_STEPS):
_, kl = self.sess.run(
[self.atrain_op, self.kl_mean],
{self.tfs: s, self.tfa: a, self.tfadv: adv, self.tflam: METHOD['lam']})
# 之后根据 kl 的值, 调整 METHOD['lam'] 这个参数
else: # 如果用 clipping 的方法
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(A_UPDATE_STEPS)]
# 更新 Critic 的时候, 他们是一样的
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(C_UPDATE_STEPS)]
最后我们看一张学习的效果图:
 (Tensorflow)")
好了这就是整个 PPO 的主要流程了, 其他的步骤都没那么重要了, 可以直接在我的 Github 看全套代码 中轻松弄懂. 接下来我们看看怎么样把这个单线程的 PPO 变到多线程去 (Distributed PPO).
Distributed PPO ¶
Google DeepMind 提出来了一套和 A3C (A3C 教程见这里) 类似的并行 PPO 算法. 看了他们 paper 中的这个 DPPO 算法后, 我觉得….不好编! 取而代之, 我觉得如果采用 OpenAI 的思路, 用他那个 “简陋” 伪代码, 但是弄成并行计算倒是好弄点. 所以我就结合了 DeepMind 和 OpenAI, 取他们的精华, 写下了这份 DPPO 的代码.
总结一下我是怎么写的.
- 用 OpenAI 提出的
Clipped Surrogate Objective - 使用多个线程 (workers) 平行在不同的环境中收集数据
- workers 共享一个 Global PPO
- workers 不会自己算 PPO 的 gradients, 不会像 A3C 那样推送 Gradients 给 Global net
- workers 只推送自己采集的数据给 Global PPO
- Global PPO 拿到多个 workers 一定批量的数据后进行更新 (更新时 worker 停止采集)
- 更新完后, workers 用最新的 Policy 采集数据
我使用的代码框架和自己的 A3C 框架有点像. 这个 DPPO 具体的代码我不会在这边描述了, 请直接看到我写的代码吧.
不过有些细节我想提前提一下, 方便你们看代码:
- 我用到了 python threading 当中的 Event 功能, 用来控制 PPO 的更新时间和 worker 停止工作的时间
- 使用了 threading 中的 Queue 来存放 worker 收集的数据, 发现用 python 的列表也可以达到一样效果, 计算时间上没太多差别.
- 更新 PPO 的时候, 我采用的是 DeepMind 的 for loop 形式.
我也用这套 DPPO 测试过自己写的机器手臂的环境, 发现效果也还行. 有兴趣的朋友可以看到这里.
有很多人留言说想要我做一个关于这个机器手臂的教程, 不负众望, 你可以在这里 看到我怎么从零开始, 手写环境, debug 测试, 来制作一个强化学习的机器手臂.
分享到:

 (Tensorflow)+|+莫烦Python&pic=https://morvanzhou.github.io/static/thumbnail-small/rl/6.4_PPO.jpg)
![]()
![]()
如果你觉得这篇文章或视频对你的学习很有帮助, 请你也分享它, 让它能再次帮助到更多的需要学习的人.
莫烦没有正式的经济来源, 如果你也想支持 莫烦Python 并看到更好的教学内容, 赞助他一点点, 作为鼓励他继续开源的动力.